Autonomous vehicles (AVs) must be able to operate in a wide range of scenarios including those in the long tail distribution that include rare but safety-critical events. The collection of sensor input and expected output datasets from such scenarios is crucial for the development and testing of such systems. Yet, approaches to quantify the extent to which a dataset covers test specifications that capture critical scenarios remain limited in their ability to discriminate between inputs that lead to distinct behaviors, and to render interpretations that are relevant to AV domain experts. To address this challenge, we introduce S3C, a framework that abstracts sensor inputs to coverage domains that account for the spatial semantics of a scene. The approach leverages scene graphs to produce a sensor-independent abstraction of the AV environment that is interpretable and discriminating. We provide an implementation of the approach and a study for camera-based autonomous vehicles operating in simulation. The findings show that S3C outperforms existing techniques in discriminating among classes of inputs that cause failures, and offers spatial interpretations that can explain to what extent a dataset covers a test specification. Further exploration of S3C with open datasets complements the study findings, revealing the potential and shortcomings of deploying the approach in the wild.
Verification and Validation of Robotic Systems
Our group is currently leading work in the following areas:
S3C: Spatial Semantic Scene Coverage for Autonomous Vehicles

Sponsors: This work was supported in part by NSF Awards #2129824 and #2312487, and AFOSR Award #FA9550-21-1-0164.
Paper Link: https://github.com/less-lab-uva/s3c/blob/main/S3C%20Spatial%20Semantic%20Scene%20Coverage%20for%20Autonomous%20Vehicles.pdf
Artifact Link: https://github.com/less-lab-uva/s3c
DeepManeuver: Adversarial Test Generation for Trajectory Manipulation of Autonomous Vehicles
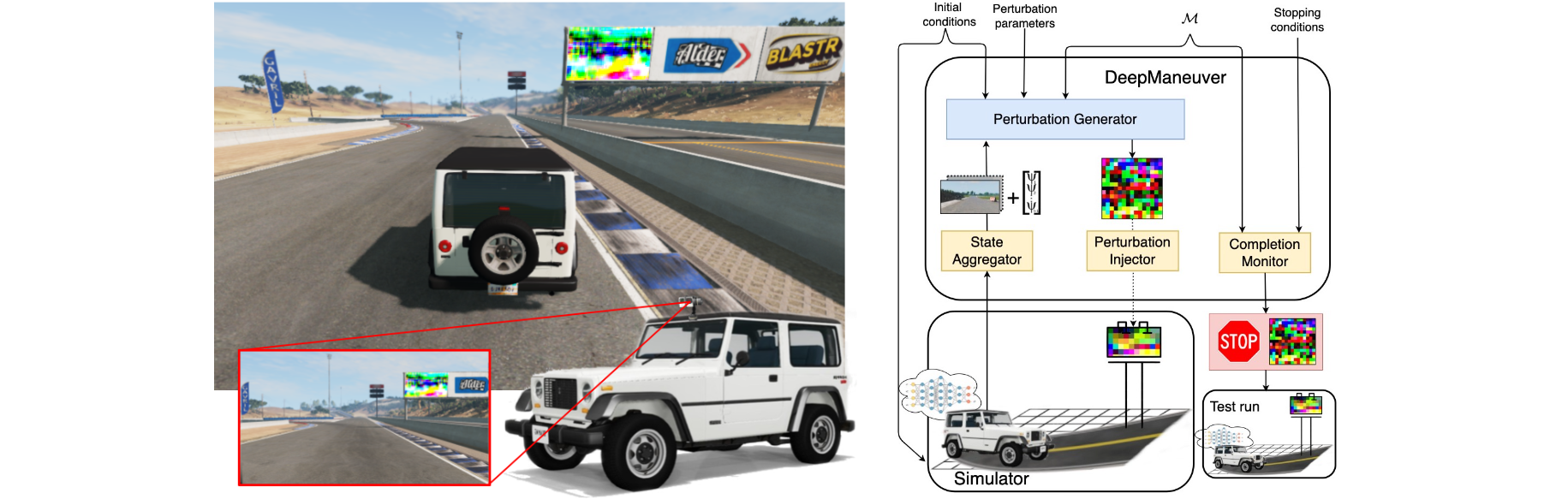
Adversarial test generation techniques aim to produce input perturbations that cause a DNN to compute incorrect outputs. For autonomous vehicles driven by a DNN, however, the effect of such perturbations are attenuated by other parts of the system and are less effective as vehicle state evolves. In this work we argue that for adversarial testing perturbations to be effective on autonomous vehicles, they must account for the subtle interplay between the DNN and vehicle states. Building on that insight, we develop DeepManeuver, an automated framework that interleaves adversarial test generation with vehicle trajectory physics simulation. Thus, as the vehicle moves along a trajectory, DeepManeuver enables the refinement of candidate perturbations to: (1) account for changes in the state of the vehicle that may affect how the perturbation is perceived by the system; (2) retain the effect of the perturbation on previous states so that the current state is still reachable and past trajectory is preserved; and (3) result in multi-target maneuvers that require fulfillment of vehicle state sequences (e.g. reaching locations in a road to navigate a tight turn). Our assessment reveals that DeepManeuver can generate perturbations to force maneuvers more effectively and consistently than state-of-the-art techniques by 20.7 percentage points on average. We also show DeepManeuver’s effectiveness at disrupting vehicle behavior to achieve multi-target maneuvers with a minimum 52% rate of success.
Sponsors: This work was supported in part by NSF Awards #1924777 and #2312487, and AFOSR Award #FA9550-21-1-0164.
Paper Link: https://ieeexplore.ieee.org/abstract/document/10213222
Artifact Link: https://github.com/MissMeriel/DeepManeuver
PhysCov: Physical Test Coverage for Autonomous Vehicles
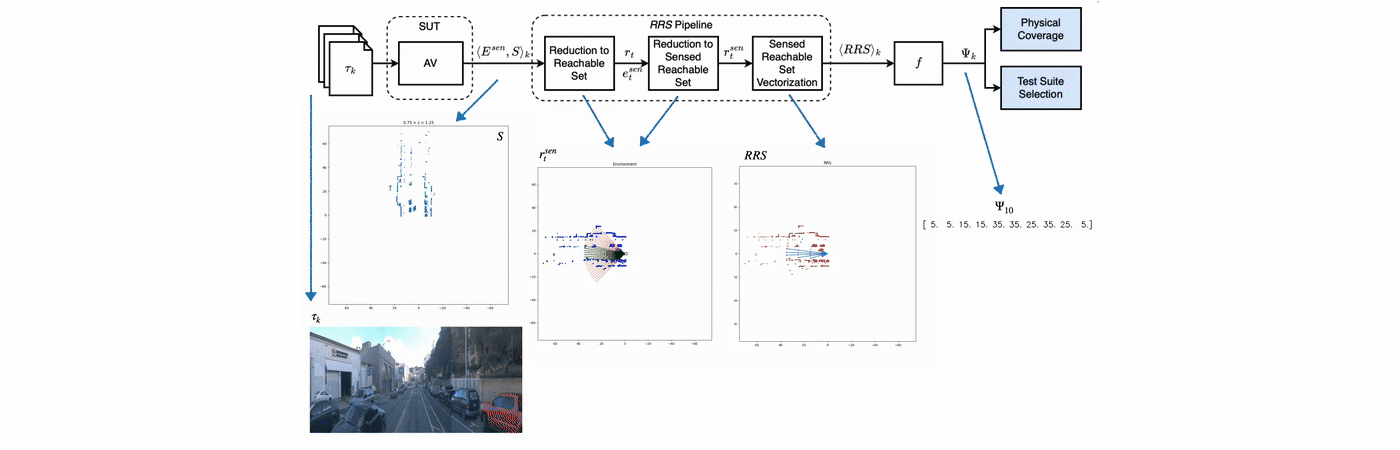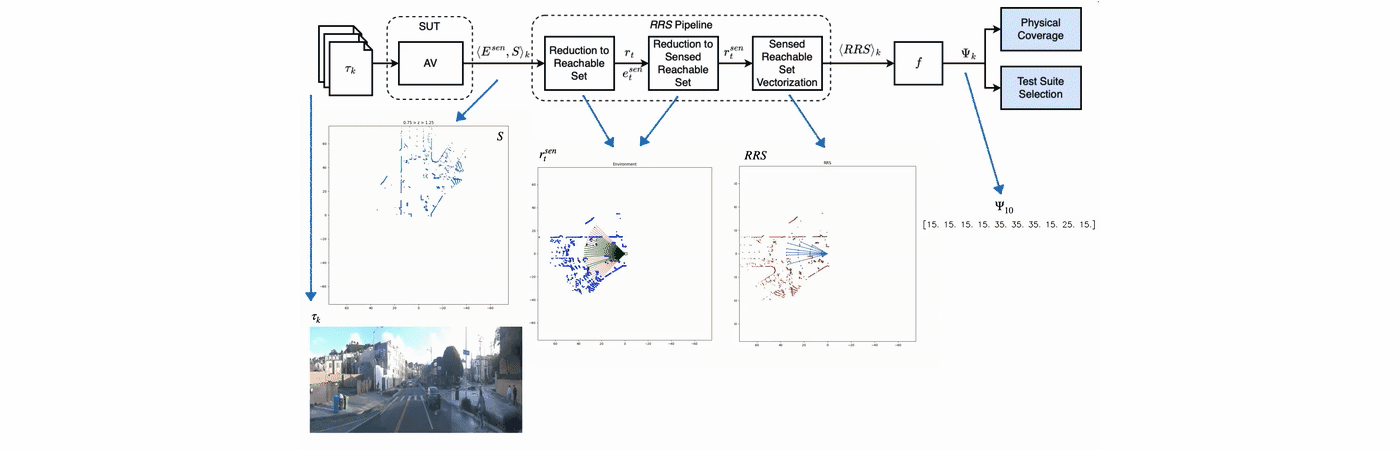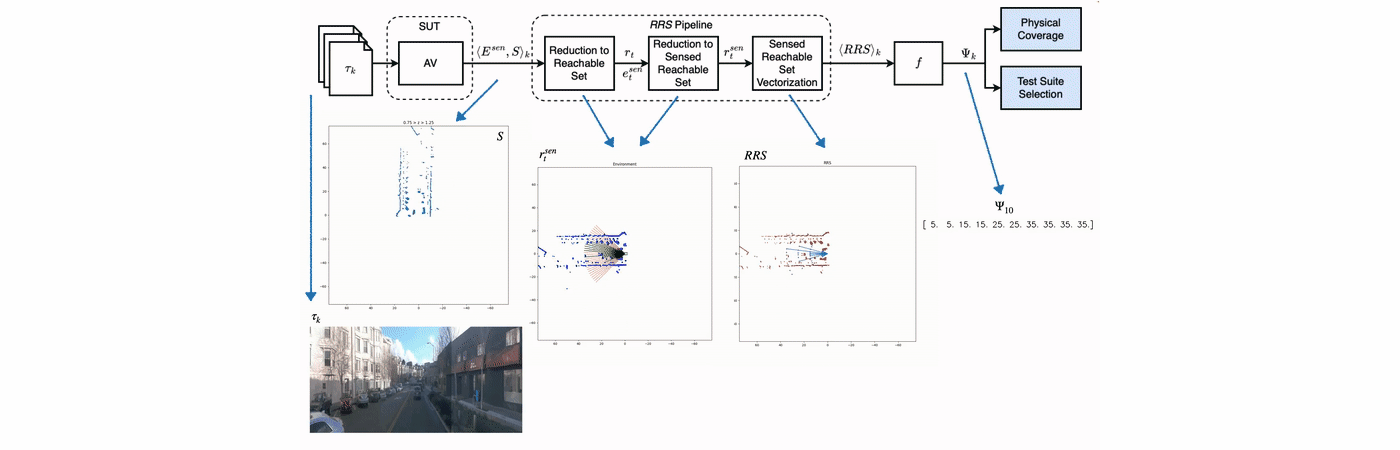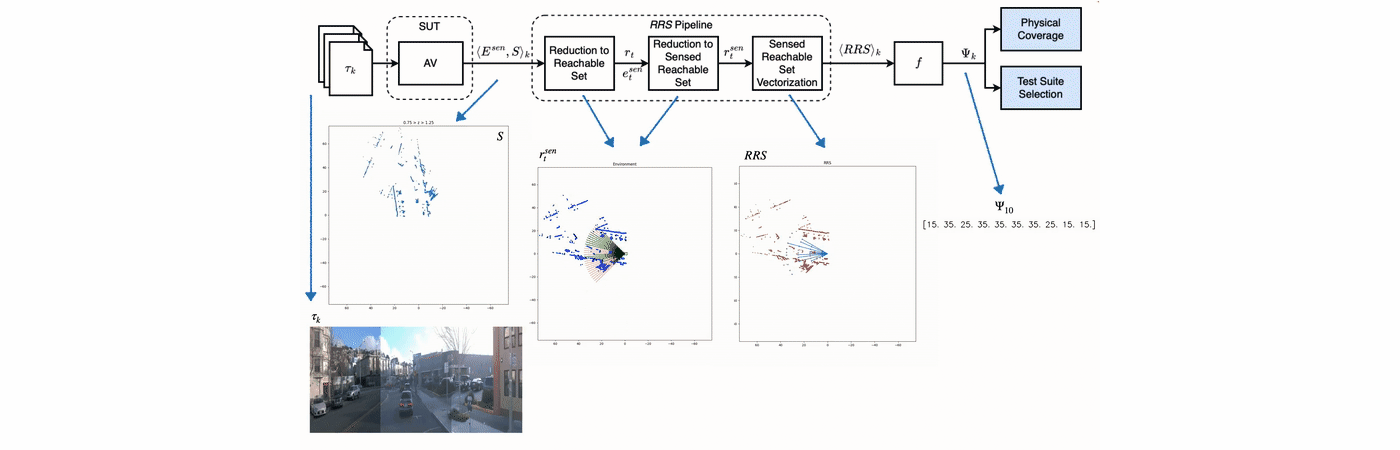
Adequately exercising the behaviors of autonomous vehicles is fundamental to their validation. However, quantifying an autonomous vehicle’s testing adequacy is challenging as the system’s behavior is influenced both by its state as well as its physical environment. To address this challenge, our work builds on two insights. First, data sensed by an autonomous vehicle provides a unique spatial signature of the physical environment inputs. Second, given the vehicle’s current state, inputs residing outside the autonomous vehicle’s physically reachable regions are less relevant to its behavior. Building on those insights, we introduce an abstraction that enables the computation of a physical environment-state coverage metric, PhysCov. The abstraction combines the sensor readings with a physical reachability analysis based on the vehicle’s state and dynamics to determine the region of the environment that may affect the autonomous vehicle. It then characterizes that region through a parameterizable geometric approximation that can trade quality for cost. Tests with the same characterizations are deemed to have had similar internal states and exposed to similar environments and thus likely to exercise the same set of behaviors, while tests with distinct characterizations will increase PhysCov. A study on two simulated and one real system’s dataset examines PhysCovs’s ability to quantify an autonomous vehicle’s test suite, showcases its characterization cost and precision, investigates its correlation with failures found and potential for test selection, and assesses its ability to distinguish among real-world scenarios. We describe this in more detail in this talk.
Sponsors: This work was funded in part through NSF grants #1924777 and #1909414, and AFOSR grant #FA9550-21-1-0164.
Paper Link: https://dl.acm.org/doi/pdf/10.1145/3597926.3598069
Artifact Link: https://github.com/hildebrandt-carl/PhysicalCoverage
Mimicking Real Forces on a Drone Through a Haptic Suit to Enable Cost-Effective Validation
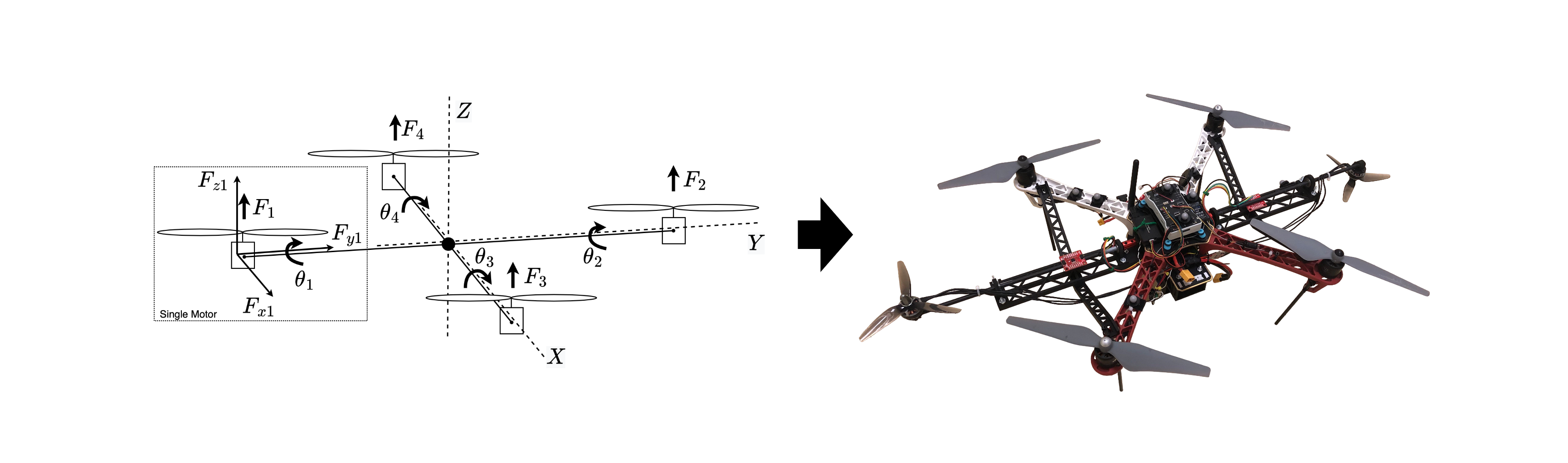
Robots operate under certain forces that affect their behavior. For example, a drone meant to deliver packages must hold its pose as long as it operates under its weight and wind limits. Validating that such a drone handles external forces correctly is key to ensuring its safety. Nevertheless, validating the system’s behavior under the effect of such forces can be difficult and costly. For example, checking the effects of different wind magnitudes may require waiting for the matching outdoor conditions or building specialized devices like wind tunnels. Checking the effects of different package sizes and shapes may require many slow and laborious iterations, and validating the combinations of wind gusts and package configurations is often hard to replicate. This work aims to overcome such challenges by mimicking external forces exercised on a drone with limited cost, setup, and space. The framework consists of a haptic suit device consisting of directional propellers that can be mounted onto a drone, a component to transform intended forces into setpoints for the suit’s directional propellers, and a controller for the suit to meet those setpoints. We describe this in more detail in this talk.
Sponsors: This work was funded in part through NSF grants #1924777 and AFOSR grant #FA9550-21-1-0164.
Paper Link: https://ieeexplore.ieee.org/stamp/stamp.jsp?arnumber=10160313
Artifact Link: https://github.com/hildebrandt-carl/HapticSuit
Generating Realistic and Diverse Tests for LiDAR-Based Perception Systems

Autonomous systems rely on a perception component to interpret their surroundings, and when misinterpretations occur, they can and have led to serious and fatal system-level failures. Yet, existing methods for testing perception software remain limited in both their capacity to efficiently generate test data that translates to real-world performance and in their diversity to capture the long tail of rare but safety-critical scenarios. These limitations are particularly evident for perception systems based on LiDAR sensors, which have emerged as a crucial component in modern autonomous systems due to their ability to provide a 3D scan of the world and operate in all lighting conditions. To address these limitations, we introduce a novel approach for testing LiDAR-based perception systems by leveraging existing real-world data as a basis to generate realistic and diverse test cases through mutations that preserve realism invariants while generating inputs rarely found in existing data sets, and automatically crafting oracles that identify potentially safety-critical issues in perception performance. We implemented our approach to assess its ability to identify perception failures, generating over 50,000 test inputs for five state-of-the-art LiDAR-based perception systems. We found that it efficiently generated test cases that yield errors in perception that could result in real consequences if these systems were deployed and does so at a low rate of false positives.
Sponsors: This work was supported in part by NSF Awards #1924777 and #1909414, and AFOSR Award #FA9550-21-1-0164.
Paper Link: https://ieeexplore.ieee.org/stamp/stamp.jsp?arnumber=10172508
Artifact Link: https://github.com/less-lab-uva/semLidarFuzz
Semantic Image Fuzzing of AI Perception Systems
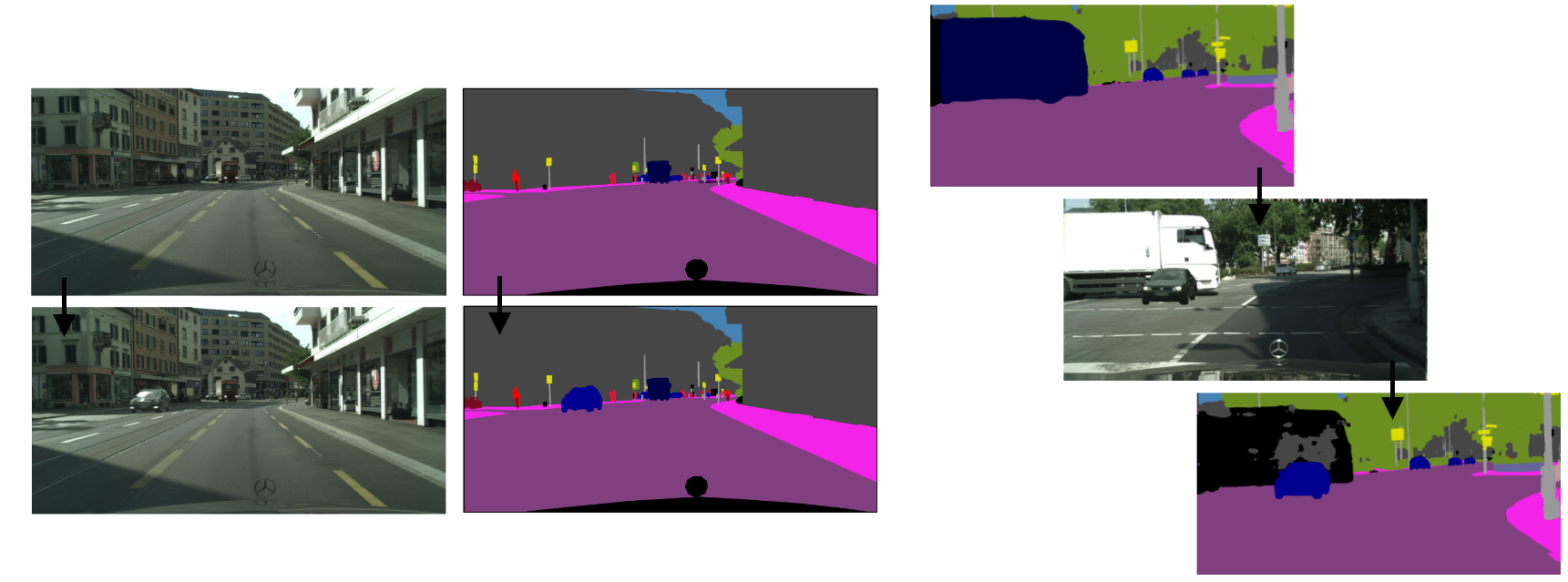
Perception systems enable autonomous systems to interpret raw sensor readings of the physical world. Testing of perception systems aims to reveal misinterpretations that could cause system failures. Current testing methods, however, are inadequate. The cost of human interpretation and annotation of real-world input data is high, so manual test suites tend to be small. The simulation-reality gap reduces the validity of test results based on simulated worlds. And methods for synthesizing test inputs do not provide corresponding expected interpretations. To address these limitations, we developed semSensFuzz, a new approach to fuzz testing of perception systems based on semantic mutation of test cases that pair real-world sensor readings with their ground-truth interpretations. We implemented our approach to assess its feasibility and potential to improve software testing for perception systems. We used it to generate 150,000 semantically mutated image inputs for five state-of-the-art perception systems. We found that it synthesized tests with novel and subjectively realistic image inputs, and that it discovered inputs that revealed significant inconsistencies between the specified and computed interpretations. We also found that it produced such test cases at a cost that was very low compared to that of manual semantic annotation of real-world images.
Sponsors: This effort is supported by NSF Awards #1924777 and #190941
Paper Link: https://dl.acm.org/doi/pdf/10.1145/3510003.3510212
Artifact Link: https://github.com/less-lab-uva/perception_fuzzing
Automated Environment Reduction for Debugging Robotic Systems

Complex environments can cause robots to fail. Identifying the key elements of the environment associated with such failures is critical for a faster fault isolation and, ultimately, debugging those failures. In this work we present the first automated approach for reducing the environment in which a robot failed. Similar to software debugging techniques, our approach systematically performs a partitioning of the environment space causing a failure, executes the robot in each partition containing a reduced environment according to an ordering heuristic, and further partitions reduced environments that still lead to that same failure as in the original world. The technique is novel in the spatial-temporal partition strategies it employs to partition and order, and in how it manages the potential different robot behaviors occurring under the same environments. Our study of a ground robot on three failure scenarios (shown above) finds that environment reductions of over 95% are achievable within a 2-hour window.
Sponsors: This effort is supported by NSF Awards #1853374 and #1924777
Paper Link: https://ieeexplore.ieee.org/iel7/9560720/9560666/09561997.pdf
Artifact Link: https://github.com/MissMeriel/DDEnv
Fuzzing Mobile Robot Environments for Fast Automated Crash Detection

Testing mobile robots is difficult and expensive, and many faults go undetected. In this work we explore whether fuzzing, an automated test input generation technique, can more quickly find failure inducing inputs in mobile robots. We developed a simple fuzzing adaptation, Base-Fuzz, and one specialized for fuzzing mobile robots, Phys-Fuzz. Phys-Fuzz is unique in that it accounts for physical attributes such as the robot dimensions, estimated trajectories, and time-to-impact measures to guide the test input generation process. We evaluate Phys-Fuzz on a Clearpath Husky robot (above left) and find that for simple test generation scenarios as shown (above right), Phys-Fuzz has the potential to speed up the discovery of input scenarios that reveal failures, finding over 125% more than uniform random input selection and around 40% more than Base-Fuzz during 24 hours of testing. Phys-Fuzz continues to perform well in more complex scenarios, finding 56.5% more than uniform random input selection and 7.0% more than Base-Fuzz during 7 days of testing.
Sponsors: This effort is supported by NSF Awards #1853374 and #1909414
Paper Link: https://ieeexplore.ieee.org/iel7/9560720/9560666/09561627.pdf
World in the Loop Simulation

Simulation is at the core of validating autonomous systems (AS), enabling the detection of faults at a lower cost and earlier in the development life cycle. However, simulation can only produce an approximation of the real world, leading to a gap between simulation and reality where undesirable system behaviors can go unnoticed. To address that gap, we present a novel approach, world-in-the-loop (WIL) simulation, which integrates sensing data from simulation and the real world to provide the AS with a mixed reality. WIL allows varying amounts of simulation and reality to be used when generating mixed reality. For example, in the figure above, the mixed reality is using the real world camera data with a simulated gate overlayed into the real world. Additionally, you can see that using WIL, we can detect bugs with a low cost of failure, as the drone collides with the gate at no physical cost to the drone. We are working on ways to expand this mixed reality with additional sensors, environments, and forces.
Sponsors: This effort is supported by NSF Awards #1853374 and #1924777
Paper Link: https://ieeexplore.ieee.org/iel7/9560720/9560666/09561240.pdf
Artifact Link: https://github.com/hildebrandt-carl/MixedRealityTesting
Testing Drone Swarm for Configuration Bugs
Swarm robotics collectively solve problems that are challenging for individual robots, from environmental monitoring to entertainment. The algorithms enabling swarms allow individual robots of the swarm to plan, share, and coordinate their trajectories and tasks to achieve a common goal. Such algorithms rely on a large number of configurable parameters that can be tailored to target particular scenarios. This large configuration space, the complexity of the algorithms, and the dependencies with the robots’ setup and performance make debugging and fixing swarms configuration bugs extremely challenging.
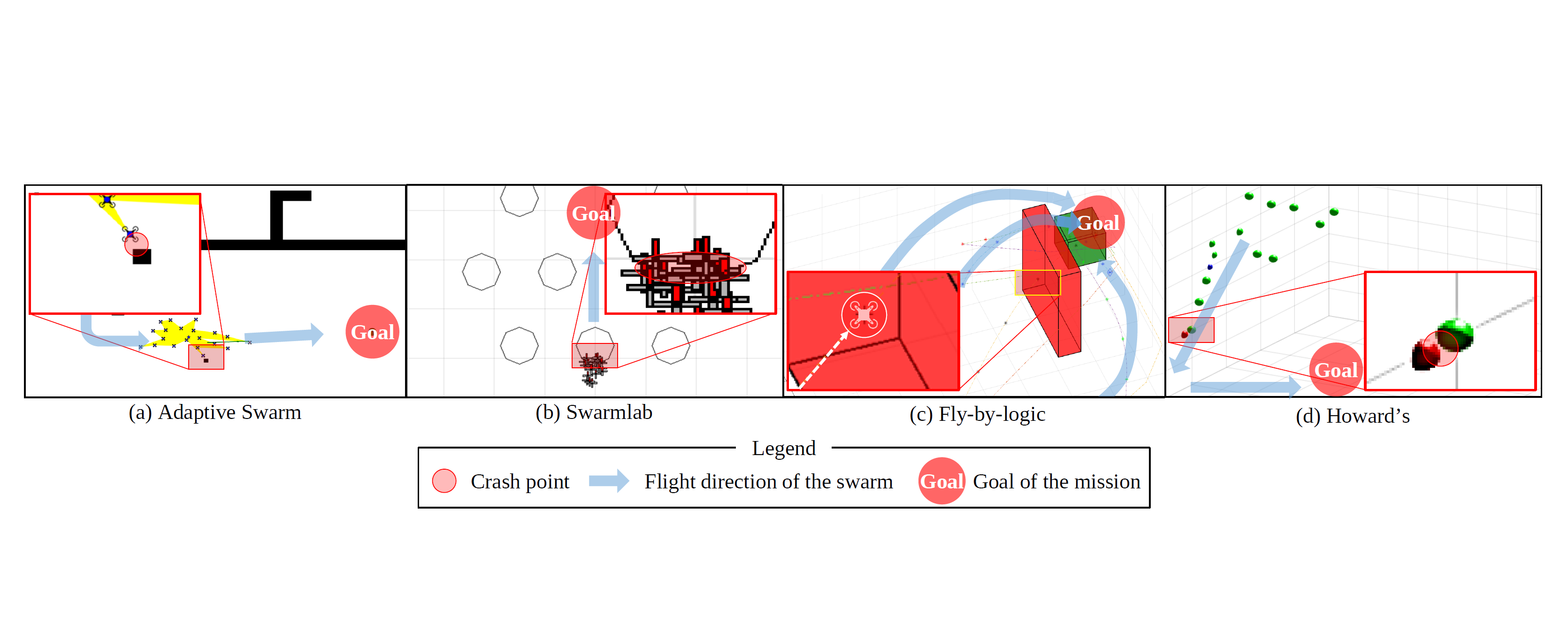
This project proposes Swarmbug, a swarm debugging system that automatically diagnoses and fixes buggy behaviors caused by misconfiguration (e.g., crashes in 4 swarm algorithms shown in the Figure). The essence of Swarmbug is the novel concept called the degree of causal contribution (Dcc), which abstracts impacts of environment configurations (e.g., obstacles) to the drones in a swarm via behavior causal analysis. Swarmbug automatically generates, validates, and ranks fixes for configuration bugs. We evaluate Swarmbug on four diverse swarm algorithms. Swarmbug successfully fixes four configuration bugs in the evaluated algorithms, showing that it is generic and effective. We also conduct a real-world experiment with physical drones to show the Swarmbug’s fix is effective in the real-world.
This figure shows buggy behaviors in four swarm algorithms: (a) drone crashes into dynamic obstacle (black square), (b) drones crash into the static obstacle (octagon), (c) drone moves to unsafe zone (red box), and (d) drone (green sphere) crashes into the static obstacle (red sphere).
Paper Link: https://dl.acm.org/doi/pdf/10.1145/3468264.3468601
Physical Semantics of Code
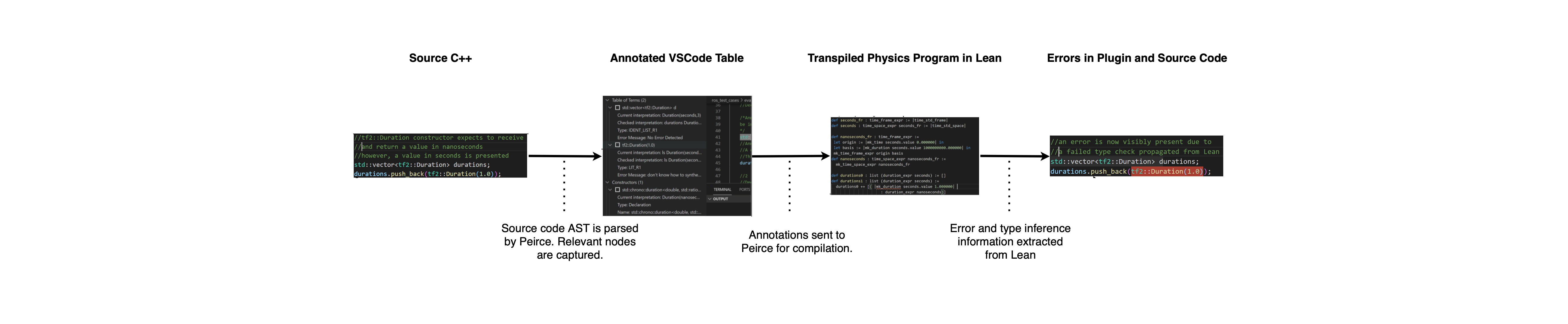
Code drives robots, space vehicles, weapons systems, and cyber-physical systems more generally, to interact with the world. Yet in most cases, code consists of machine logic stripped of real world semantics. This means that there is no way for the computing machine to prevent operations specified in code from violating physical constraints inherited from the physical world. Traditional programming semantics can tell us that the expression, 3.0 + 4.0 means 7.0, in the sense that 7.0 is the result of evaluating that expression. But our traditional conception of programming semantics does not address the questions, 3 of what, 4 of what, or 7 of what, or whether such a sum makes any physical sense. For example 3 meters plus 4 grams does not make physical sense. Major systems malfunctions have occurred due to the machine-permitted evaluation of expressions that have no well defined physical meanings.
To improve the safety and reliability of cyber-physical systems, we are developing and evaluating Peirce, a software infrastructure to pair software code with interpretations that map terms in code to formal specifications of their intended physical meaning (such as points, vectors, and transformations) so that the consistency of code with the physics of the larger system can be automatically checked. Peirce takes annotated source code and, using its formalized physical types in higher-order logic of a constructive logic proof assistant, determines the consistency of those physical types usages. We are currently targeting and evaluating Peirce on robotics programs using ROS. For example,
Feasible and Stressful Trajectory Generation for Mobile Robots

While executing nominal tests on mobile robots is required for their validation, such tests may overlook faults that arise under trajectories that accentuate certain aspects of the robot’s behavior. Uncovering such stressful trajectories is challenging as the input space for these systems, as they move, is extremely large, and the relation between a planned trajectory and its potential to induce stress can be subtle. Additionally, each mobile robot will have a unique set of physical constraints that define how the robot can move. Thus, we need to ensure that the trajectories generated are feasible given the robot’s physical constraints. This work aims at combining both a physical model of the mobile robot and a parametrizable scoring model to allow for the generation of physically valid yet stressful trajectories for mobile robots. We show an example of a stressful trajectory on the upper right where a sharp turn results in the drone overshooting its waypoint and colliding with the wall. We describe how we did this in more detail in this talk.
Sponsors: This effort is supported by NSF Awards #1853374 and #1901769 as well as the U.S. Army Research Office Grant #W911NF-19-1-0054
Paper Link: https://dl.acm.org/doi/pdf/10.1145/3395363.3397387
Artifact Link: https://github.com/hildebrandt-carl/RobotTestGeneration
Blending Software and Physical Models for Testing Autonomous Systems

This research aims at finding ways to ensure the safety and validity of autonomous systems; a non-trivial problem. This problem is non-trivial and unique because of two fundamental issues. First, these systems have an unconstrained input space due to them operating in the real world. Second, these systems rely on technology, such as machine learning, that is inherently statistical and tends to be non-deterministic. This research recognizes the dual nature of autonomous systems, namely that they contain both physical and software elements that interact in the real world. The insight that we can harness information from the physical models of autonomous systems as well as information from software analysis is unique and has numerous benefits. For example, improving the accuracy of a system’s physical model by incorporating software constraints into the physical model. We describe this in more detail in this talk.
Sponsors: This effort is supported by NSF Award #1718040
Paper Link: https://dl.acm.org/doi/pdf/10.1145/3377816.3381730